Awesome AI Speech Recognition Tools in 2024
Discover the awesome 2 AI tools for 2024 By Candytools
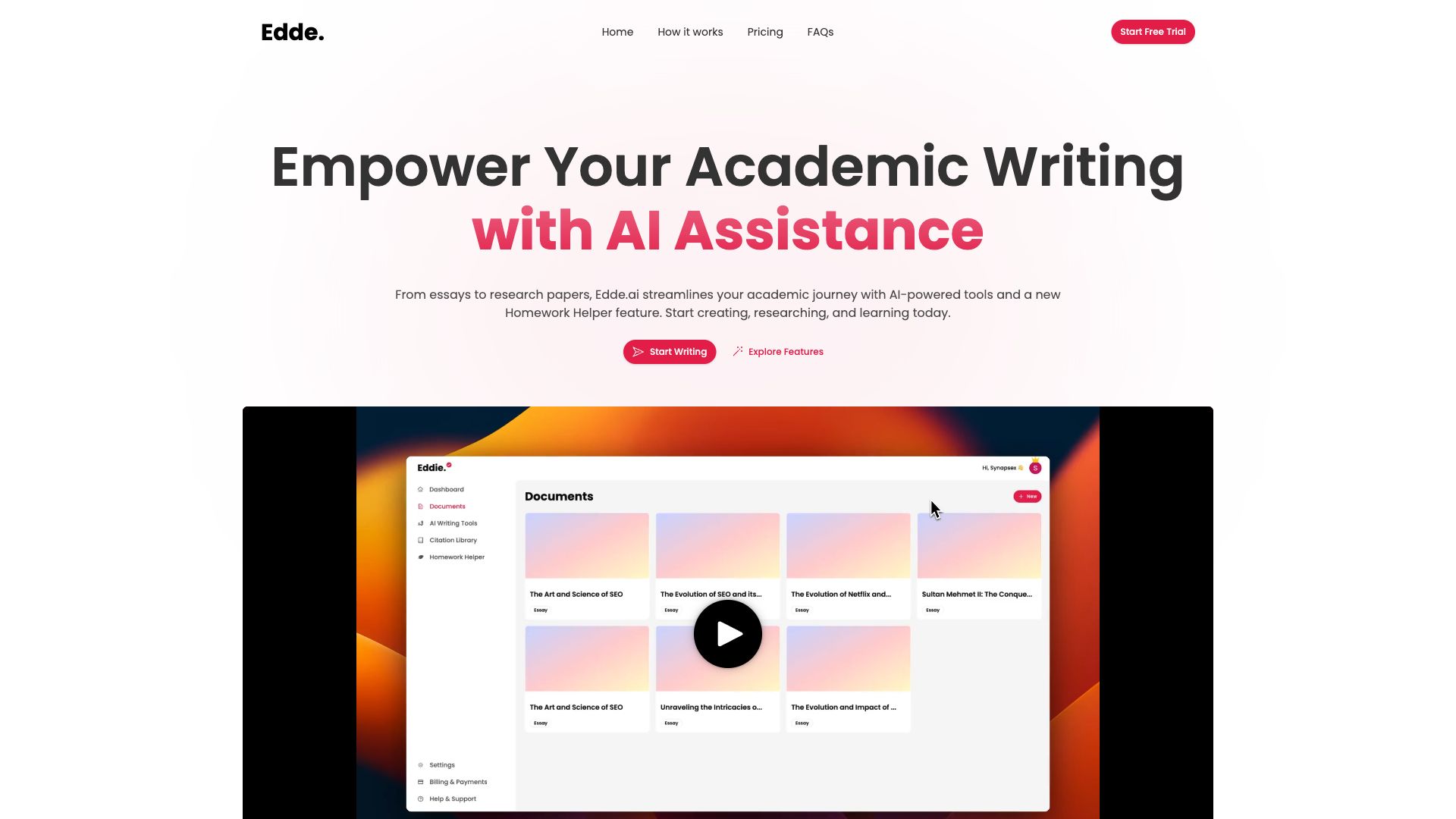
From essays to research papers, Edde.ai streamlines your academic journey with AI-powered tools and a new Homework Helper feature. Start creating, researching, and learning today.
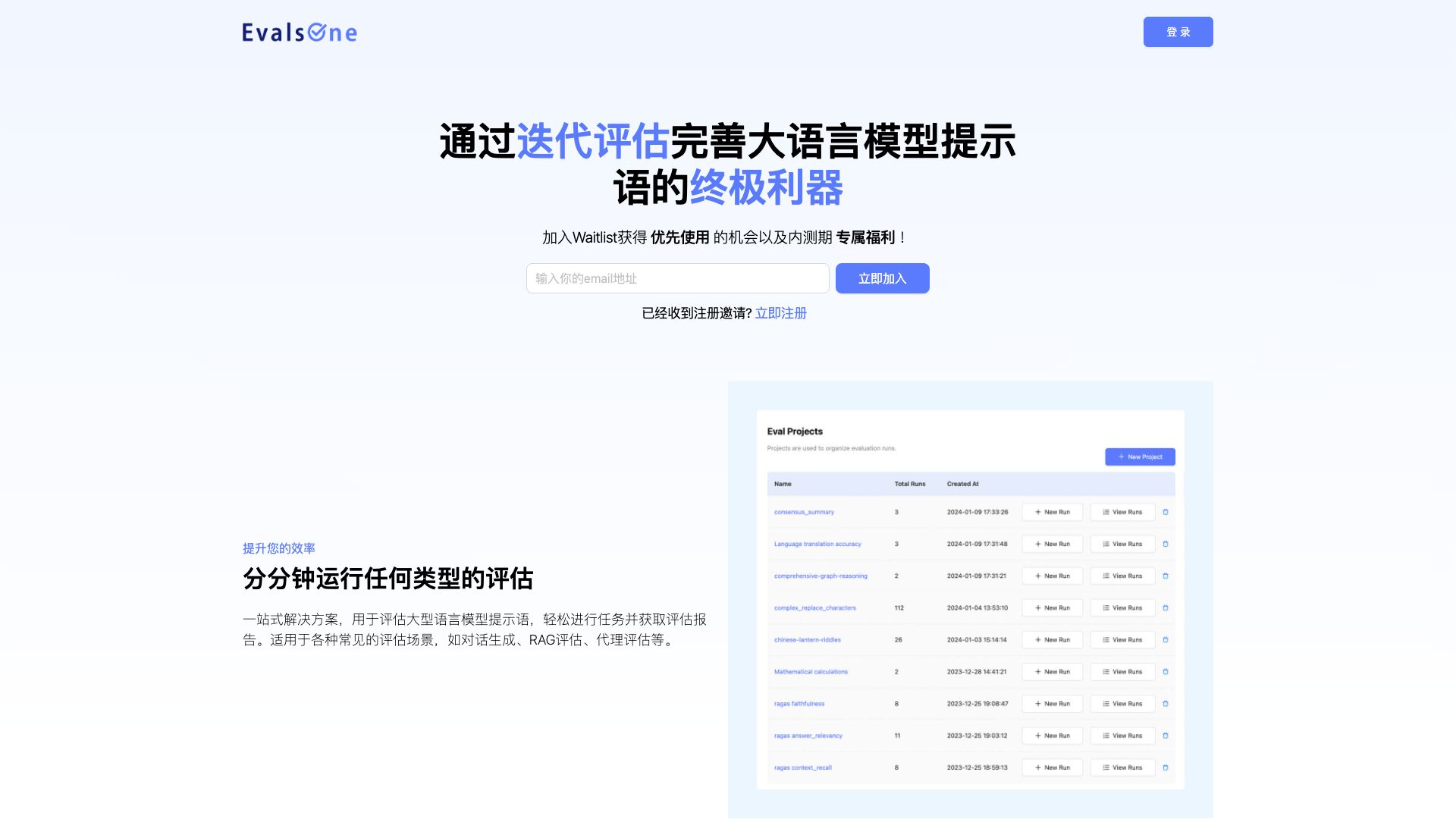
Your premier platform for iteratively developing and perfecting generative AI applications
More AI Tools Categories
What is AI Speech Recognition?
AI speech recognition, also known as automatic speech recognition (ASR), is the capability of a computer or device to accurately transcribe spoken language into text. This technology is powered by artificial intelligence, specifically machine learning algorithms that are trained on massive amounts of audio data and corresponding transcripts.
Here's how AI speech recognition generally works:
-
Audio Input: The system receives an audio signal, which could be from a microphone, audio file, or another source.
-
Feature Extraction: The audio signal is processed to extract relevant features that represent the sounds of speech. These features might include:
- Acoustic Features: Spectrograms, Mel-frequency cepstral coefficients (MFCCs), or other representations of the frequency content and timing of the speech.
- Phonetic Features: Information about the individual speech sounds (phonemes) being uttered.
-
Acoustic Modeling: The extracted features are fed into an acoustic model, which is a statistical representation of how sounds are produced in a particular language. This model helps the system distinguish between different speech sounds.
-
Language Modeling: A language model, which is a statistical representation of word sequences and grammar in a language, is used to predict the most likely words that follow each other. This helps improve accuracy and resolve ambiguities in the recognized speech.
-
Decoding and Transcription: The system combines the output of the acoustic model and language model to determine the most likely sequence of words that corresponds to the input audio. This sequence is then output as transcribed text.
Applications of AI Speech Recognition:
- Virtual Assistants: Siri, Alexa, Google Assistant
- Dictation and Transcription: Converting speech to text for documents, emails, or meeting minutes.
- Voice Search: Searching the internet or controlling devices using voice commands.
- Accessibility: Enabling individuals with disabilities to interact with technology using their voice.
- Customer Service: Automating call centers and providing self-service options through voice interfaces.
Benefits of AI Speech Recognition:
- Efficiency: Automating tasks that previously required manual typing or data entry.
- Accessibility: Providing a more natural and intuitive way to interact with technology.
- Personalization: Enabling personalized experiences based on voice commands and preferences.
- Multilingual Support: Speech recognition systems can be trained to recognize various languages.
Challenges in AI Speech Recognition:
- Background Noise: Filtering out unwanted sounds from the environment.
- Speaker Variability: Accurately recognizing speech from different speakers with varying accents, dialects, and speaking styles.
- Emotional Speech: Interpreting emotions and nuances in human speech.
The Future of AI Speech Recognition:
- Improved Accuracy: AI models continue to improve, leading to more accurate and reliable speech recognition.
- Enhanced Natural Language Understanding: Systems are becoming better at understanding context and intent in spoken language.
- Personalized and Adaptive Learning: Speech recognition will become more personalized, adapting to individual user's speech patterns and preferences.
- Integration with Other AI Technologies: Speech recognition will be seamlessly integrated with other AI technologies, such as natural language processing and computer vision, to enable more powerful and intelligent applications.